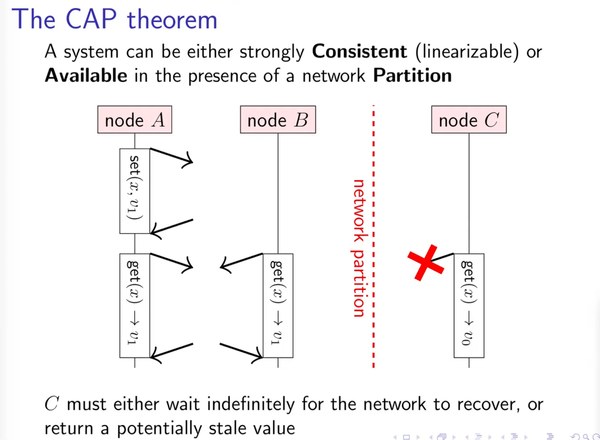
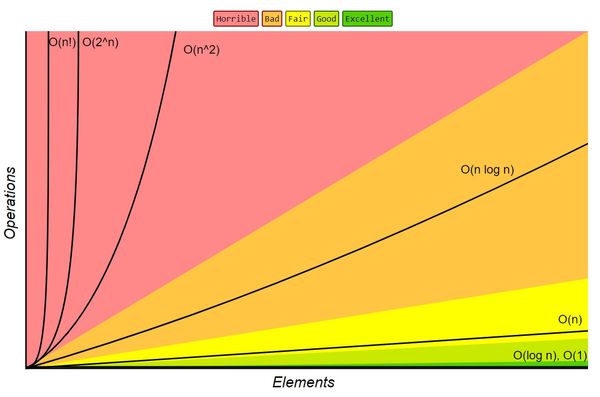
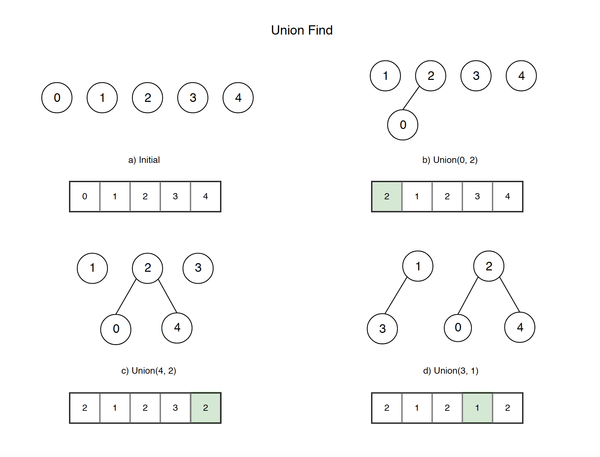
I recently finished reading the book I've heard a lot of. Both authors are well-known Software Architects with dozen years of experience. Mark Richards, for example, runs great bi-weekly Software Architecture Monday lessons.
I want to share my opinion about this book, save some notes I made, and explain why